



Bij Scenius claimen we, net als de meeste anderen, een performant en scalable software solution te bieden. Maar ‘scalability’ en ‘performance’ is voor de meesten een moeilijk te vatten begrip. Wat definieert ‘scalability en performance’ en moet je je zorgen maken? Bij het ontwikkelen of onderhouden van een softwareproject is het belangrijk om continu te beoordelen of de oplossing de bedrijfsdoelstellingen van vandaag kan ondersteunen tot de laatste dag van de verwachte levensduur van het product. In deze blogpost zullen we uit leggen hoe we de performance-related non-function requirement formuleren en hoe we valideren en monitoren dat aan deze eisen wordt voldaan. Dit is ook waar load testing en application performance monitoring (APM) een rol gaan spelen.
Click here for the English version 👉 click
Moet ik me druk maken over scalability en performance?
Kortom, ja, altijd, maar in welke mate verschilt sterk afhankelijk van het doel van de software. Scalability en performance zijn maatstaven voor de efficiëntie van software, de eerste een maatstaf voor het effect en de inspanning van zowel horizontaal als verticaal groeien van de applicatie, en de laatste een indicatie van de hoeveelheid workload die het systeem kan verwerken. Bij Scenius kijken we graag naar het grotere geheel, een deel daarvan komt neer op het identificeren van flows in een systeem. Waar een flow vaak een of meerdere user stories zijn die door een (virtuele) gebruiker worden uitgevoerd om een bepaald doel te bereiken.
Bij Scenius hebben we verschillende klanten die actief zijn in e-commerce, dus laten we voor de rest van deze blogpost als voorbeeld flow een online betaling nemen.
Wanneer je applicatie snel is en wanneer juist niet
Ongeacht het aantal klanten dat je wilt faciliteren met je checkout, de performance van de applicatie moeten boven acceptabel zijn. Een goede indicatie van de performance is de tijd die de applicatie nodig heeft om op een actie of verzoek te reageren. Voor ons voorbeeld van een online betaling is het belangrijk dat de gebruiker vooruit kan in de flow, dus een snappy requirement is een must. ‘Snappy’ is subjectief en onmetelijk, daarom meten we de latency van individuele acties in milliseconden. Wij hanteren de volgende interne richtlijn:
Onder 50 ms: Uitstekend
50-100ms: Goed
100-150ms: Aanvaardbaar
150-250ms: Twijfelachtig
250 ms+: Reageert niet
Er zijn enkele nuances in deze lijst. Bijvoorbeeld bij externe integraties of geografische uitdagingen. De flow vereist een inline API call naar een externe partij die niet binnen een acceptabel tijdsbestek reageert, dan kan het onmogelijk worden om aan de non-function requirement te voldoen. Wel zijn wij van mening dat het de verantwoordelijkheid van de ontwikkelende partij is om deze beperkingen onder de aandacht van de klant te brengen, zodat deze door de integrerende partij kunnen worden aangepakt.
Wanneer we onze prestatietest uitvoeren, doen we dit meestal vanuit een stabiele glasvezelverbinding naar hyperscalers, niet vanaf onze telefoons die in de trein zitten die door een tunnel gaat. Daarom zijn we kritisch met betrekking tot de synthetische belasting tests, we moeten compenseren voor de echte wereld.
Is je applicatie wel echt scalable?
Wat is een scalable applicatie? Simpel gezegd als de throughput een minimale impact heeft op de latency (Latency wordt gebruikt om de tijd die gegevens nodig hebben om van het ene naar het andere punt en terug te gaan, uit te drukken. Latency is eigenlijk de vertraging tussen het moment waarop u een actie uitvoert en het resultaat.). Een vaak gemaakte fout is wanneer aannames van scalability worden gemaakt op basis van applicatieprestaties tijdens ontwikkeling, acceptatie en pre-prod. De applicatie wordt als snel ervaren, dus wordt aangenomen dat deze schaalbaar moet zijn, maar wanneer 10 gebruikers de applicatie tegelijkertijd gebruiken is de applicatie onbruikbaar. Nu zijn we aangekomen bij de tweede belangrijke non-function requirement, throughput (De hoeveelheid data die door een netwerk kan worden afgeleverd binnen een bepaalde tijd. Vrij vertaald de snelheid van een netwerk). We drukken de throughput uit in gelijktijdige transacties per seconde (TPS), dus als we een TPS van 60 hebben, zou de applicatie 60 checkout flows per seconde moeten kunnen voltooien. Het is belangrijk om vast te stellen hoeveel gebruikers je met de softwareoplossing wilt faciliteren.
Laten we met ons e-commercevoorbeeld zeggen dat je verwacht elke maand 10.000 eenheden te verkopen en dat je binnen 3 jaar wilt opschalen naar 100.000 transacties. Nu nemen we een (realistisch) worst case scenario, je verkoopt een luxe cadeau-product, het is eind december en met de feestdagen in aantocht krijgen de meeste mensen op de zelfde dag hun loon.
Dit levert ons 2500 transacties per uur op voor het eerste jaar en 25000 transacties na drie jaar voor dit geval. Dit komt neer op 2.8TPS en 28TPS.
Voor dit voorbeeld zouden we 30+TPS instellen als onze non-function requirement.
Hoe wij in de praktijk testen met Elastic en K6
In deze repository hebben we een klein project opgezet om te illustreren hoe te testen met k6 en mogelijke knelpunten te identificeren. Deze test is puur voor verticaal schalen, plaats zeker een comment als je benieuwd bent naar een blog over de manier waarop wij klanten faciliteren in de reis naar de cloud, kubernetes en het verifiëren van horizontale schaalbaarheid. 💡
Bekijk hier de complete repository 👉 https://github.com/scenius-software/blogpost-loadtest/tree/feature/proposal-1
Ingrediënten van deze test zijn:
- Voorbeeldtoepassing: eenvoudige toepassing met één langzaam eindpunt
- Elasticsearch: de backing datastore voor onze APM-data
- Elastic APM: de instrumentatietool die wordt gebruikt om de prestaties van onze app te controleren
- Kibana: Elastic’s gebruikersinterface die kan worden gebruikt om onze APM-gegevens te visualiseren
- Postgres: de backing-database voor de voorbeeldtoepassing
De voorbeeld applicatie bevat één test endpoint dat een langzame database call, een langzame integratiepartner en een concurrency limit simuleert.
[HttpGet]
public async Task<IActionResult> GetOrders()
{
// Simulate slow database performance
var orders = _db.OrderLines.Where(x => x.Product.Name.Length > 3).Average(x => x.Quantity * x.Product.WidthCentimeters);
try
{
// Simulate concurrency issues
await _concurrencyLatch.WaitAsync();
// Simulate slow integration partner
await _httpClient.GetAsync("https://deelay.me/5000/https://scenius.nl");
}
finally
{
_concurrencyLatch.Release();
}
return Ok(orders);
}Om een baseline vast te stellen voeren we een enkele oproep uit vanuit de browser.
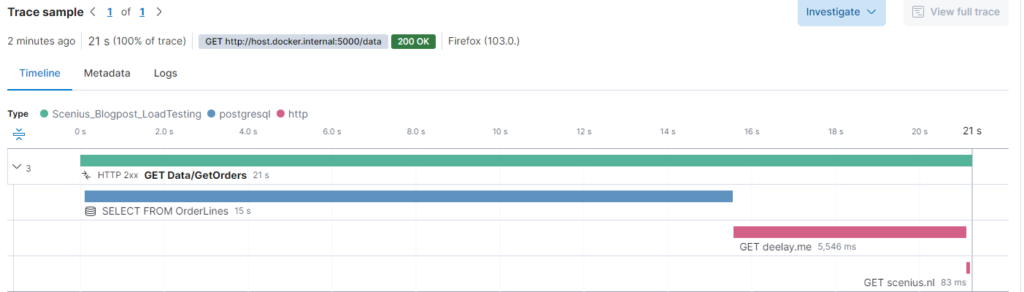
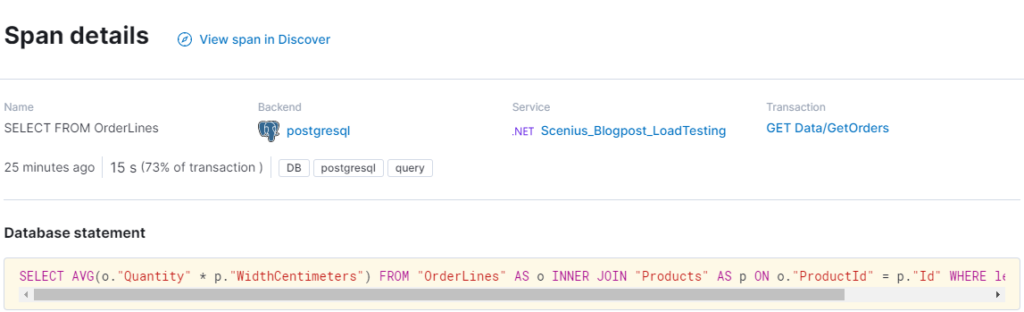

Nadat we onze query hebben verbeterd, zien we nu dat de database binnen 25 milliseconden reageert. Helaas zijn we afhankelijk van een externe partner Deelay.me. In de echte wereld nemen we meestal contact op met de verkoper of partner en vragen we of dit wordt verwacht en wat we kunnen doen om het aan hun kant op te lossen. Anders kunnen wachtrijen, caches en mirroring worden toegepast. Laten we aannemen dat ze het probleem oplossen.

Tijd voor load testing
Op dit moment hebben we een endpoint met een lage latency, nu is het tijd om te zien hoe het werkt onder belasting. Hiervoor gaan we k6 gebruiken, een van de vele beschikbare load-test tools. We gebruiken k6 voornamelijk omdat het gemakkelijk is.
- Minder ingewikkeld dan bijvoorbeeld JMeter
- Meer performant met een enkele testing node
- K6 heeft een gebruiksvriendelijkere manier van instellen
Het script in de repository simuleert 100 virtuele gebruikers die herhaaldelijk de site bezoeken met een iteration delay van 1000 ms.
Laten we zeggen dat voor deze toepassing de vereiste 30TPS @ 100 gebruikers is met een maximum van 95e percentiel van 150MS respons. We zullen k6 instrueren om gedurende 3 minuten op te schalen naar 100 gebruikers.
stages: [
{ duration: '30s', target: 100 }, // Ramp up
{ duration: '2m', target: 100 }, // Hold
{ duration: '30s', target: 0 }, // Ramp down
],
thresholds: {
'http_req_duration': ['p(95)<150'], // 99% of requests must complete below 1.5s
}Na de test krijgen we de volgende resultaten van k6:
After the test we get the following result from k6.
running (3m00.9s), 000/100 VUs, 1536 complete and 0 interrupted iterations
default ✓ [======================================] 000/100 VUs 3m0s
data_received..................: 680 kB 3.8 kB/s
data_sent......................: 129 kB 713 B/s
http_req_blocked...............: avg=33.55µs min=0s med=0s max=1.19ms p(90)=0s p(95)=505.82µs
http_req_connecting............: avg=31.26µs min=0s med=0s max=1.19ms p(90)=0s p(95)=505.49µs
✗ http_req_duration..............: avg=8.98s min=78.91ms med=10.26s max=12.06s p(90)=11.24s p(95)=11.4s
{ expected_response:true }...: avg=8.98s min=78.91ms med=10.26s max=12.06s p(90)=11.24s p(95)=11.4s
http_req_failed................: 0.00% ✓ 0 ✗ 1536
http_req_receiving.............: avg=693.39µs min=0s med=557.05µs max=14.29ms p(90)=1.56ms p(95)=1.86ms
http_req_sending...............: avg=5.01µs min=0s med=0s max=617.4µs p(90)=0s p(95)=0s
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=8.98s min=78.49ms med=10.26s max=12.06s p(90)=11.24s p(95)=11.4s
http_reqs......................: 1536 8.492113/s
iteration_duration.............: avg=9.99s min=1.07s med=11.27s max=13.08s p(90)=12.25s p(95)=12.41s
iterations.....................: 1536 8.492113/s
vus............................: 3 min=3 max=100
vus_max........................: 100 min=100 max=100
ERRO[0181] some thresholds have failedOm dit te verifiëren gebruiken we Elastic APM:
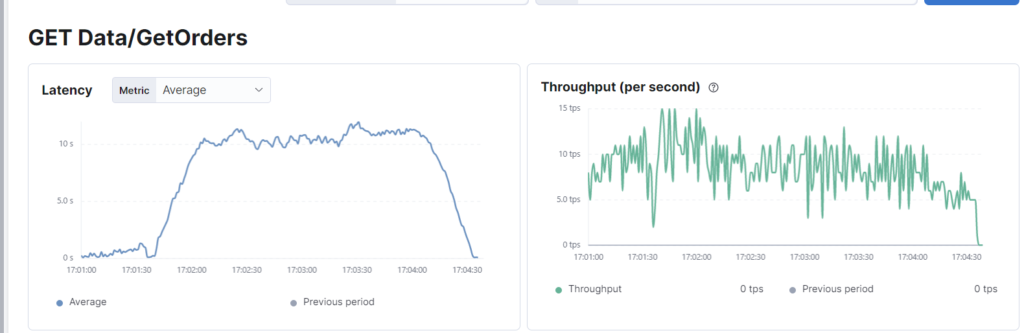
Tot verbazing van degenen die alleen tests voor één gebruiker uitvoerden, vernietigde deze eenvoudige synthetische werklast de applicatie met een gemiddelde responstijd van 8980 milliseconden. De toepassing voldoet niet aan de gecombineerde prestatievereiste van latency en throughput. Zoals eerder geïllustreerd, reageert ditzelfde eindpunt in minder dan 20 milliseconden wanneer een enkele gebruiker het raakt, dus als er geen rekening werd gehouden met de throughput, zou het alleen zijn gepasseerd om in productie te exploderen.
We hebben een concurrency issue met het lock gesimuleerd, maar dit kan vele oorzaken hebben, zoals table-locking of slecht presterende integraties. Wanneer er een verband is tussen het verhogen van de virtuele gebruikers en
Laten we dit opnieuw proberen zonder een concurrency issue. De database lijkt voor onze query op 2,5-4 ms te zijn ingesteld en we zullen het resultaat van de HTTP-aanroep in de cache opslaan, omdat we weten dat deze voornamelijk statische gegevens retourneert.
running (3m00.5s), 000/100 VUs, 14694 complete and 0 interrupted iterations
default ✓ [======================================] 000/100 VUs 3m0s
data_received..................: 1.4 MB 7.5 kB/s
data_sent......................: 1.2 MB 6.8 kB/s
http_req_blocked...............: avg=5.46µs min=0s med=0s max=1.4ms p(90)=0s p(95)=0s
http_req_connecting............: avg=3.57µs min=0s med=0s max=1.24ms p(90)=0s p(95)=0s
✓ http_req_duration..............: avg=16.66ms min=9.76ms med=15.92ms max=100.23ms p(90)=17.49ms p(95)=23.63ms
{ expected_response:true }...: avg=16.66ms min=9.76ms med=15.92ms max=100.23ms p(90)=17.49ms p(95)=23.63ms
http_req_failed................: 0.00% ✓ 0 ✗ 14694
http_req_receiving.............: avg=93.52µs min=0s med=0s max=9.04ms p(90)=410.5µs p(95)=515.7µs
http_req_sending...............: avg=5.91µs min=0s med=0s max=920.1µs p(90)=0s p(95)=0s
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=16.56ms min=9.52ms med=15.82ms max=100.23ms p(90)=17.28ms p(95)=23.62ms
http_reqs......................: 14694 81.427997/s
iteration_duration.............: avg=1.02s min=1.01s med=1.02s max=1.1s p(90)=1.03s p(95)=1.03s
iterations.....................: 14694 81.427997/s
vus............................: 2 min=2 max=100
vus_max........................: 100 min=100 max=100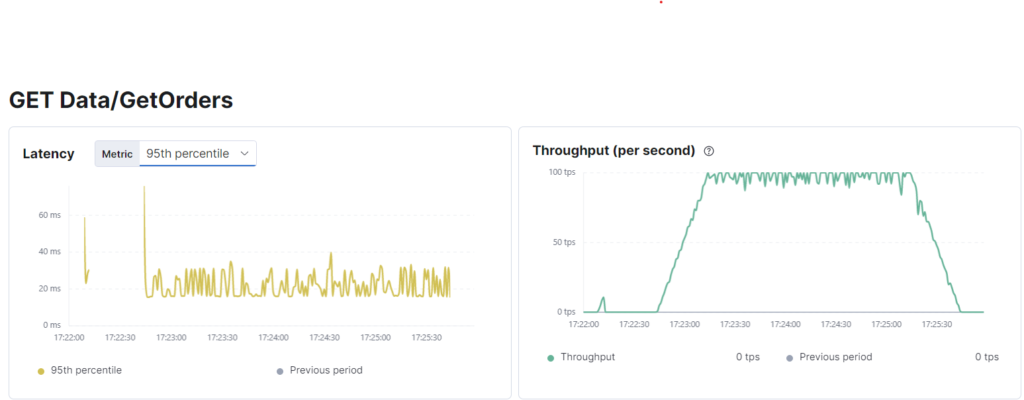
Zoals we kunnen zien, meldt k6 81TPS en dit wordt bevestigd door Elastic. Aangezien we 100 virtuele gebruikers hebben met een cyclusvertraging van 1 seconde, is dit meer dan acceptabel en nadat we de vereiste wijzigingen hebben aangebracht, is onze voorbeeldtoepassing nu geslaagd.
Blijf ook zeker monitoren
Met behulp van Elastic’s dashboards is het mogelijk om langzame endpoints te vinden, de hoofdoorzaak te identificeren en te rapporteren over de impact op de gebruikers. Kibana kan ondersteunen bij het instellen van waarschuwingen voor latency verhogingen en andere parameters die kunnen wijzen op een slecht presterend endpoint. Er zijn tal van andere oplossingen die hetzelfde doel dienen, namelijk valideren dat aan de non-functional requirements die in het verleden zijn gesteld en gevalideerd, nog steeds wordt voldaan, zelfs nadat de actieve ontwikkeling is beëindigd.
Bij Scenius nemen we operationele monitoring zeer serieus, vooral omdat we veel integraties hebben die een aanzienlijke impact kunnen hebben op de diensten van onze klanten. Door slecht presterende integraties te identificeren en leveranciers te waarschuwen, kunnen service outages worden voorkomen.
Ervoor zorgen dat de applicaties binnen je IT-landschap hun bedrijfsdoelstellingen kunnen ondersteunen, is cruciaal. Hoewel vaak over het hoofd gezien in de snel veranderende scale-up mindset, spelen non-functional requirements een belangrijke rol, vooral wanneer de groei van het gebruikersbestand de beperkingen van de concurrency overtreft.
We raden aan om alle vitale flows te identificeren en non-functional requirements in te stellen met vermelding van de verwachte TPS met een P95 latency threshold en periodieke rapportage hierover aan te vragen bij je softwareleverancier.
Ben jij benieuwd of jouw applicatie voldoet? Neem gerust contact met ons op en we helpen je graag verder!


